The easier way to handling large files in pandas

I'm Fares Hasan, a passionate Data Scientist with a track record of driving innovation in machine learning and data analytics. As a seasoned leader, I thrive on building high-performing teams and implementing cutting-edge solutions that solve complex business challenges. With expertise in technical data science, machine learning, and data infrastructure, I'm dedicated to fostering a culture of growth, collaboration, and excellence. I'm also deeply passionate about Semantic Search and, in my spare time, have been exploring the frontiers of AI through the development of a Retrieval Augmented Generation (RAG) system. Let's connect to explore opportunities at the intersection of data, AI, and innovation.
Cute panda from pixabay
I have been using a high-performance laptop for some time and EC2 machine for when I needed high computing power. I never encountered issues of performance for as long as I remember with both tools giving me quite a comfortable processing power. Things started to seem awfully different when I downgraded my MacBook and cannot enjoy the privileges of high computing powers on my disposal.
This has forced me to dig down and learn more about Pandas library. So if you are trying to learn about tips to handle your multiple gigabytes files in Pandas this gonna help you. To my surprise batch processing wasn’t the easiest way around handling your file, well in most of the times you are looking into a way to reduce the files size without getting into batch processing.
Data types in Pandas
As you know in python we have several variants of the same data type. So for integers, we have int16, int32, int64 and for floats, we have float16,float32, float64. These are extra memory capacities that we might or might not need. Pandas library in default it reads your data in the 64 variant. So, your age column will be between 1–99 and it will be assigned to int64 data type.
Int64 is 8 bytes and can store the figure -9223372036854775807 up to + 9223372036854775807. The question is do you really need int64 for your age column? This is the question you have to ask yourself for each column in your dataset. When you know the answer then it will be easy for you to shrink the size into something hopefully your machine can handle.
In a nutshell, you need to give each column the proper data type without instead of the Pandas library default type.
Shrinking your file by 87.5%
I have a CSV file of 2.2 gigabytes in size and shape 117180 * 2502 for a sparse matrix that I take me a lot of time to load each time I run my Jupiter notebook. I will demo for you how I can take this file into something my machine can handle.
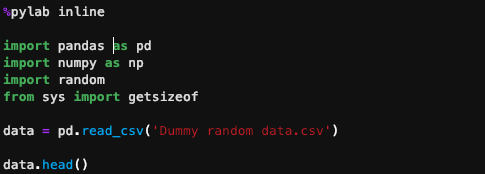
Loading my file (dummy data
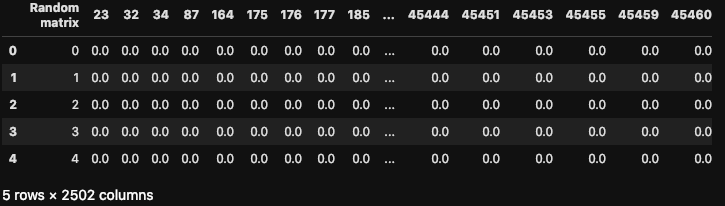
my dataset as it look
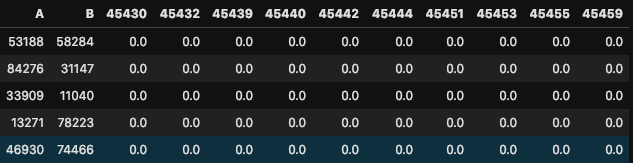
a few more columns
As you see I have the majority of the columns with small values or Zero values and just two columns with integers that are not large per se. The int16 data type can store values from -32768 to +32768. We technically can use this for our A and B column in this dataset.
Let’s look at the data frame info:
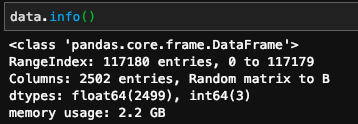
Look at the dtypes
We can check the file size and convert it to gigabytes using the following:
start_size = getsizeof(data)/(1024.0**3)
print('Dataframe size: %2.2f GB'%start_size)
Converting column data types in pandas
In my case, there are so many columns to be exact its 2502 columns and by no means, I can go through each column so I used a for loop to convert all the columns of the data frame.
for col in data.columns:
data[col] = pd.to_numeric(data[col], downcast='signed')
Now you may ask what is the downcast parameter? Simply if your columns are float64 like the dataframe I have above, downcast will simply convert them into float16 and if the case they are int it will downcast to the smallest variant of the data type.
downcast takes only the following values: {‘integer’, ‘signed’, ‘unsigned’, ‘float’}
- ‘integer’ or ‘signed’: smallest signed int dtype (min.: np.int8)
- ‘unsigned’: smallest unsigned int dtype (min.: np.uint8)
- ‘float’: smallest float dtype (min.: np.float32)
If you are to use the to_numeric method for each line then you will have to something of the form of:
bigfile['A'] = pd.to_numeric(bigfile['A'], downcast='signed')
bigfile['B'] = pd.to_numeric(bigfile['B'], downcast='signed')
For my 2.2 gigabytes file, the for loop took quite some time and this is why you should find better ways to perform the conversions. The result of this conversion was that my file went down on size to:
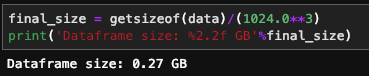
Do you want to know the percentage?
print('total size reduction: %2.1f'%((1-final_size/start_size)*100))
Size reduce by 87.5%
For me, this has solved my issue and cannot let pandas assigned all type 64 to my columns because most of the time the values are too small and therefore the efficient use of memory is the solution for now.
I hope this helps you to navigate around large files (large for mediocre machines I mean) and you can crunch more data.
Have a happy new year….
2019




