I've always had a taste for fresh, leafy greens in my salads. Yet, as I embarked on my urban farming journey, I often found myself disappointed by the limited variety of fresh produce available in my local market. The store-bought options either lacked the freshness I craved or were just unavailable. It was on one of these fruitless shopping trips that I realized growing my own vegetables at home was the only way to enjoy the robust and varied salads I had in mind.
As I started cultivating my own urban garden, I found myself facing a steep learning curve. There were times when I struggled to identify what my plants needed, and my inexperience made it difficult to find effective solutions. It was during these moments of uncertainty that I realized the value of having an accessible, reliable source of information. My mind drifted back to the remarkable capabilities of large language models, and an idea began to take root.
The Spark
What if I could create an AI plant care assistant that could make the expertise and knowledge required for successful gardening available to anyone? Inspired by the challenges I faced in my own garden and the potential of AI to revolutionize plant care, I set out to create Casia. I imagined a world where the power of AI could democratize gardening, making it more accessible and enjoyable for everyone. My personal struggles with finding fresh vegetables for my salad were replaced by a sense of purpose, knowing that I was building a tool that could help countless urban farmers and plant enthusiasts nurture their green spaces with confidence.
The hackathon
When I heard about the Pinecone Hackathon, a spark of excitement ignited within me. I realized that this competition could be the perfect platform to build an AI-powered tool that is really useful. One of the requirements was to build a web or phone application so I went to talk to a couple of friends and told them they loved the idea of an AI-powered plant care assistant. This has given me the spirit to register my newly founded team that is 100% remote and just wants to build something real.
The Pinecone Hackathon offered me not only the opportunity to create my AI assistant but also the resources to do so. It provided access to AI tools like openai, cohere and even hugginface, AWS credits, and a supportive community of like-minded individuals. This environment was a stark contrast to my solitary journey in pondering LLM-powered solutions. As part of the hackathon, I would be able to collaborate with others who shared my enthusiasm for AI and my commitment to sustainability. This was proven when a few individuals reached out to me after the hackathon expressing their love for Casia.
Building Casia
Building Casia required multiple skills and different stages to make this vision a reality. I will explain here what we built and how we exactly built it. The core concept in which Casia was built is called Retrieval Augmented Generation or RAG. This type of system expands the knowledge of the AI LLM and enhances it with specific types of data. In our case here the expectation is that we want to reduce confabulations and increase accuracy by providing additional knowledge to the model. This data is structured and sourced from various databases, forums etc of urban gardening and relevant topics.
Foundational models like GPT3/4 and others are trained offline and they are agnostic to any data or domain that is created after the model was trained. Now if you want the model to be robust in performing for a specific problem domain you have two ways. Finetuning, however, is expensive, requires expertise and is not the right solution. Finetuning is the way if you want the model to acquire a new skill. In our case, we want the model to have more knowledge and that can be done with building a RAG system.
I gathered data from various resources and I tried my best that this data provided valuable context to plant care along with information on the plant names in case it was being called by different names (like scientific name and common name). These chunks of data will have the following pieces about each plant:
Description: names and varieties of the plant if any
Suitable weather: the origin of the plant, what weather and temps for it to thrive
Disease: any known diseases and how to prevent them
Care: watering and light instructions to grow a healthy plant
Different platforms have different ways to present the data and we have tried our best to make these four points present so that our model shares sound advice later on.
Creating the knowledge base
To create a RAG system you need two components. An embedding model and a vector database. Let's explain embedding. In the core of the RAG system, we are employing a technique called semantic search and this is what requires the embedding.
Embedding is a process in which our text data is converted into a vector. This vector is a mathematical representation of our piece of text. This representation is robust nowadays in giving us insights about the semantics of the text which is a level above the language syntax. This is to say that having the vector gives us the ability to understand the meaning of the text on a contextual level rather than the literal translation of the words. This is the power of semantic search.
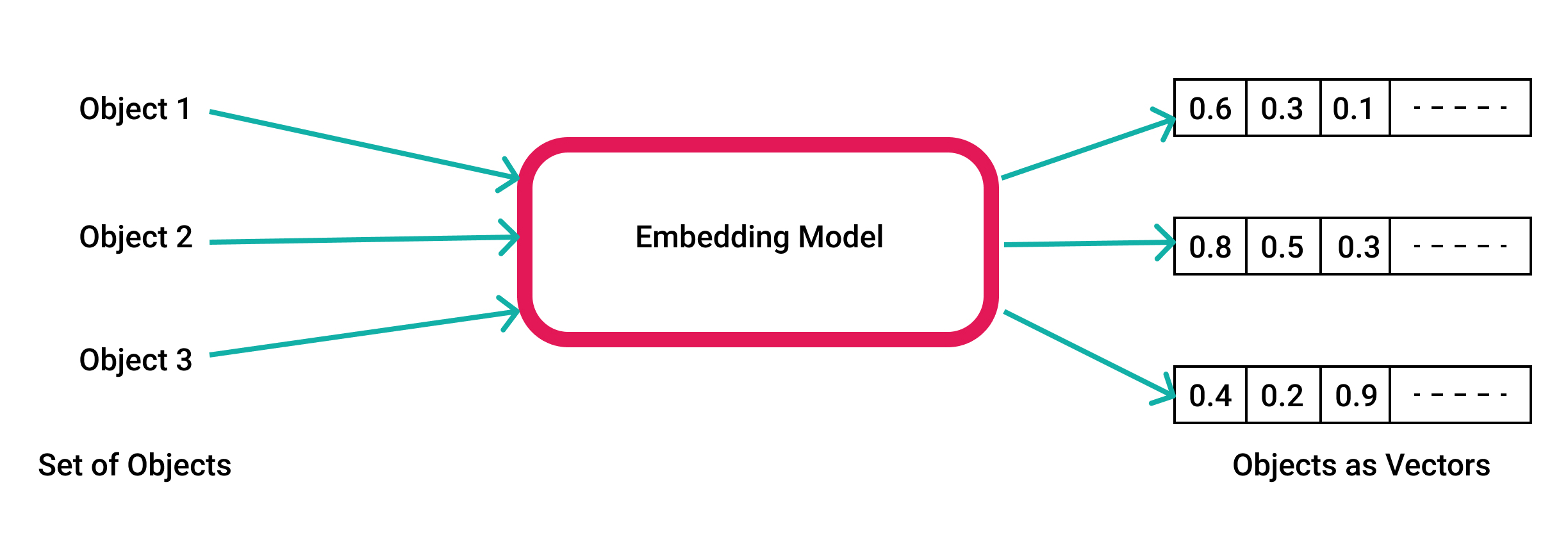
How is this going to help in our application?
Imagine someone searching for caring tips about some plant that belongs to the genus Aloe (the species that Aloe vera belongs to). If you are searching with text matching you might not be able to infer systematically that the user is inquiring about some aloe vera cousin. However, by doing a semantic search we will be able hopefully to infer this relationship and others if existed systematically and present all of this info to our model before answering the user question.
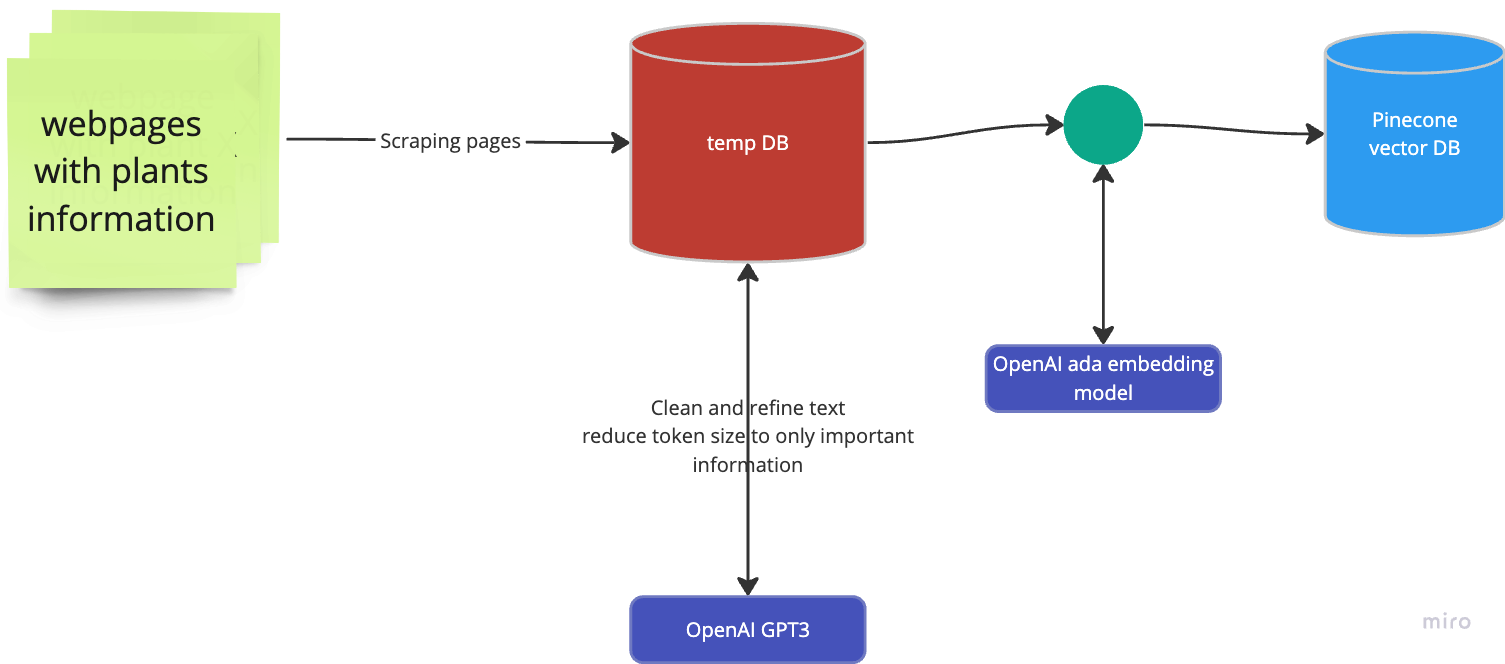
This diagram represents our processing from collecting the plant information till we have a knowledge base created and stored in the vector database. This hackathon is by Pinecone which is the vector database we have to use as the core technology.
Retrieval
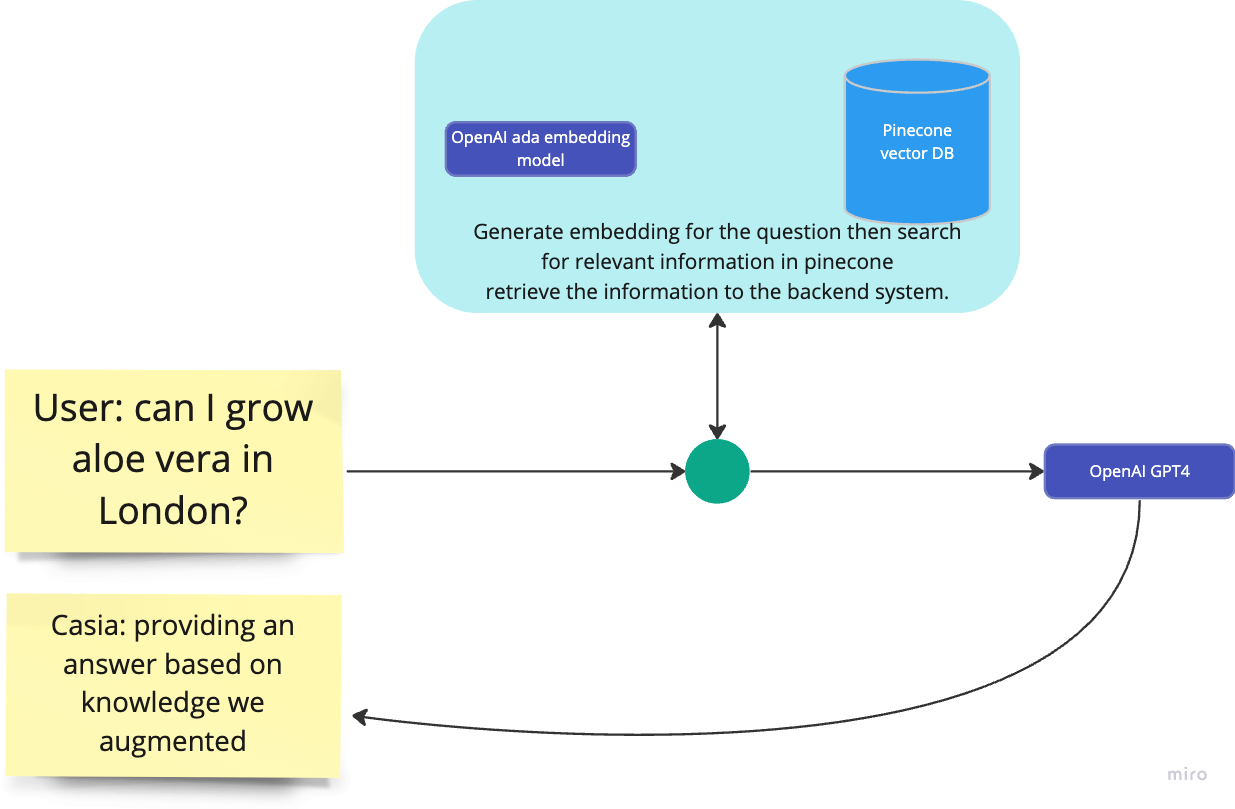
R in RAG stands for retrieval and I am sure you want to know how this work at a conceptual level. Earlier we learned that the core of the RAG system is the semantic search technique. In operation, we approach the question answering as a search problem. When a user asks a question we have to search in the vector DB for information that is semantically relevant to the user question. This information is then fed to the GPT4 model with the user question to generate the answer. Hence the name retrieval augmented generation. Here is a diagram that resembles this process:
Application
Our mobile application was built by my friend ABDULMALEK AL-SHUGAA using Expo go and Aref Asaket been in the backend. All the core components related to the RAG system are built into endpoints using fastapi which makes up our AI microservice that is integrated into the backend.
Challenges
Building Casia wasn't always smooth sailing. Like any significant endeavour, it came with its fair share of struggles and obstacles. From technical hurdles to moments of doubt, the journey was full of unexpected challenges.
One of the most significant technical challenges I encountered was ensuring that the AI model could accurately recognize and classify a wide range of plant species. Differentiating between various plants required a substantial amount of data, which wasn't always easy to come by. As mentioned in the RAG system part I have to devise creative methods for data collection, including crowdsourcing and web scraping. But all of this data might not always be in the format and shape or inclusive of the information that is needed.
Evaluating the system performance was another issue that is hard to solve at least with the tools or problem we have at hand. Merely at how the system can answer 3 random questions doesn't constitute statistical significance. However, we have to take our system at face value by observing how it performs in a few questions.
Apart from the technical challenges, I also experienced moments of doubt during the hackathon. The time constraints and pressure of the competition made it challenging to stay focused on the end goal. There were moments when I wondered if the effort was worth it, or if I was pursuing the right idea.
Cost and token size were additional concerns. Every time a user sends even a "Hi" message our system will go into full gear doing the RAG thing and semantic searching. This has been funny and completely unnecessary but I thought we shouldn't burden our system to RAG the hell out of every message. We have solved this by using another cohere model dedicated to answering short questions like this. It gave us a small room to only unleash the RAG power when the question is more than a few tokens in size, not a perfect approach but it works.
As for the token size we have to shorten our chunks of data when building the knowledge base. In addition to this, we have limited the use of the retrieved data to the top 3 results only. If you guessed using the 16k token window from the openAI GPT3.5 model, you are right we have used that version of the model after spending a lot of time being unaware of its existence.
Conclusion
I'm tremendously excited about the potential of projects like Casia to revolutionize the world of plant care and other domains. By democratizing knowledge and harnessing the power of AI, we can make plant care accessible to everyone, regardless of their background or experience. Imagine a world where anyone can easily grow their own food, create beautiful gardens, or simply enjoy the company of healthy houseplants without the steep learning curve that often accompanies these endeavours.
The potential of AI to bring positive change goes beyond plant care. In education, healthcare, and other critical sectors, AI can democratize access to information and resources, enabling more people to lead fulfilling lives. With projects like Casia, we're taking steps toward a more equitable, sustainable, and connected world where technology serves as a tool for empowerment and progress.
As for the future of Casia, unfortunately, I have not planned anything beyond the hackathon. I am open to any initiatives that would want to adopt my simple system and take to serve more audiences and perhaps grow beyond my initial vision.
Thank you for taking the time to read I really appreciate you spending your time on this. Feel free to share with your friends and spread the post.
If you want to know more feel free to comment and ask away. Also here is the repository if you want to look into our code for the RAG system




