Rethinking AI Training: Lessons from the 'Textbooks is All You Need' Study
How Microsoft Research's Emphasis on Textbook-Quality Data is Paving the Way for More Efficient and Responsible AI

I'm Fares Hasan, a passionate Data Scientist with a track record of driving innovation in machine learning and data analytics. As a seasoned leader, I thrive on building high-performing teams and implementing cutting-edge solutions that solve complex business challenges. With expertise in technical data science, machine learning, and data infrastructure, I'm dedicated to fostering a culture of growth, collaboration, and excellence. I'm also deeply passionate about Semantic Search and, in my spare time, have been exploring the frontiers of AI through the development of a Retrieval Augmented Generation (RAG) system. Let's connect to explore opportunities at the intersection of data, AI, and innovation.
Introduction
In an era where magnitude is frequently equated with mastery, the realm of artificial intelligence (AI) has been fervently chasing the creation of ever-larger and more intricate models. The prevailing belief among tech giants seems to be that grandeur in AI is synonymous with greatness. Yet, what if our perspective has been skewed? Drawing inspiration from the insightful findings of Microsoft Research in "Textbooks is All You Need" I invite you on a journey to explore an alternative viewpoint. This is a brief summary of the most important highlights of performance, comparison, and findings of the team.
The Importance of High-Quality Data
In the rapidly evolving landscape of artificial intelligence, data stands as the foundation upon which models are built. The age-old adage "garbage in, garbage out" has never been more relevant than in the context of training AI models. Imagine feeding a child a diet of misinformation. Over time, this child will develop a skewed perception of the world. In much the same way, when we feed our AI models "dirty data," they develop flawed understandings.
The quality of data determines not just the efficacy of the model, but also its efficiency, ethical implications, and real-world applicability.
The findings from Microsoft Research's "Textbooks is All You Need" only serve to emphasize this cardinal principle. The recent "textbooks are all you need" study shows that like humans, AI thrives when it learns from clean, high-quality data.
The paper fundamentally demonstrates that having "textbook quality" data can be a game-changer for AI training. Instead of using vast datasets that often contain noise, redundancies, or even errors, the researchers showed that curating a high-quality dataset — akin to a well-structured textbook — dramatically improves the learning efficiency of language models for code.
Efficient Learning

The research showcased that their model, phi-1, trained on high-quality data, surpassed the capabilities of most open-source models on coding benchmarks like HumanEval and MBPP. Remarkably, this was achieved even though phi-1 is smaller in terms of model size and was trained on a dataset that's 100x smaller than what many other models utilize.
Taking a closer look at model performances, GPT3.5's massive size of 175B stands out when compared to phi-1's smaller 1.3B. However, it's interesting to note that, when tested on the HumanEval metric, phi-1 still manages to outpace GPT3.5, proving that bigger isn't always better.
Mimicking Human Learning
The most effective human learners seek out high-quality educational resources—well-written textbooks, knowledgeable teachers, and clear lessons. AI models, in essence, are no different from these learners. They are digital students. For them, “textbook quality” data, as showcased in the recent research, should become the benchmark.
Here's my own summary of their approaches:
Filtering with GPT-4's Aid: Before diving into large-scale model training, they used GPT-4 to annotate the quality of a small subset of code samples. It's akin to having an expert review a chapter before publishing a textbook, ensuring what gets included is of high instructional value.
Synthetic Textbook-Quality Datasets: Emulating the essence of textbooks, they didn't just rely on organic code samples. They employed GPT-3.5 to generate synthetic Python textbooks. This method served a dual purpose:
Provides a rich source of explanatory text combined with relevant code snippets, similar to textbook lessons and examples.
Introduces diversity by setting constraints, ensuring the model encounters varied coding scenarios and doesn’t just memorize a few patterns.
Focus on Basic Algorithmic Skills: The content specifically targeted promoting reasoning and fundamental coding skills, much like a beginner’s textbook.
Emphasis on Function Completion: With the CodeExercises dataset, the model was trained to take a function description and generate corresponding code, akin to problem-solving exercises in textbooks. This not only tested the model's understanding but also its application skills.
Careful Decontamination: Just like how textbooks are revised to remove errors, the team was vigilant in ensuring that their training data didn't contain problems that the model would directly encounter during evaluations, avoiding any undue advantage.
Impact and Performance Details
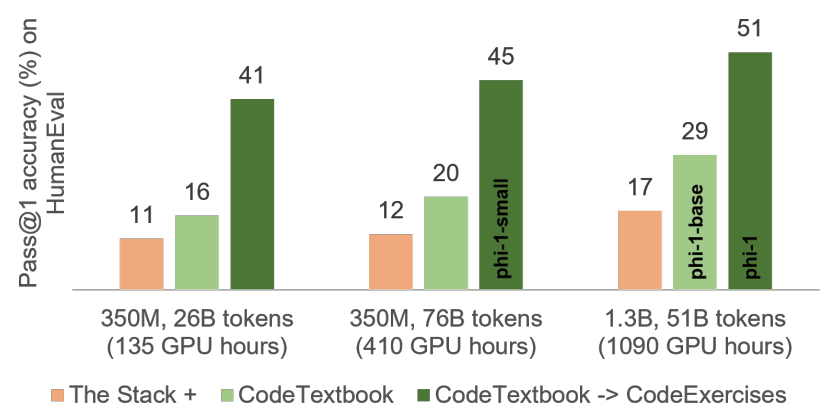
These bars are grouped together to illustrate distinct aspects:
How Hard the Model Works: Think of it as varying study durations – from a quick skim to an in-depth study session. It ranges from sifting through 26B bits of data to a whopping 76B.
Size of the Model: Models come in sizes, these bars also represent models of varying 'sizes'. The spectrum extends from a moderate 350M to a more substantial 1.3B.
Within each of these categories, three unique columns emerge, representing distinct training sets:
The Standard Source (Orange Bars): This represents how models fared when trained using regular Python files, commonly sourced from platforms like StackOverflow. Picture this as the outcome of learning from widely available study materials.
Their Unique Mix (Light Green Bars): The next column represents models trained on 'CodeTextbook', or tailored dataset. Imagine a curriculum that’s been customized for optimal learning with greater connotations of examples and contexts. (the new dataset curated by the researchers)
Exercises Boost (Dark Green Bars): The last set signifies how models did after some extra practice sessions using 'CodeExercises'. Think of it as reinforcing knowledge with exercises after a lesson.
when the researchers augmented their model with the 'CodeExercises', it's score skyrocketed to 51% on the identical test. Furthermore, it astounded them with its remarkable coding capabilities. Hence, it's evident that armed with optimal training materials and a touch of practice, smaller models can indeed rival, if not surpass, their larger counterparts!
Overcoming the Shortcomings of "Dirty Data"
The Microsoft Research team noted several challenges with commonly used datasets. Picture this: attempting to learn a complex subject from a textbook filled with fragmented explanations, missing sections, and occasionally, even misinformation.
Many of the coding snippets in these standard datasets weren't ideal for teaching the intricate nuances of algorithmic reasoning. They frequently lacked the necessary context, often presenting oversimplified or trivial examples. It's akin to trying to understand a deep philosophical concept from only a single quote. Moreover, there were instances where these snippets were accompanied by insufficient documentation, leaving the AI model to 'guess' its way forward.
The implications of such "dirty" data are vast. Models trained on flawed datasets might produce unreliable or incorrect outputs. They may struggle to generalize beyond their training, faltering when presented with real-world challenges. In essence, their foundation is shaky, potentially leading to inefficient or even incorrect decision-making.
The Power of Smaller, Finely-Tuned Models
In our quest for AI supremacy, we've often assumed that larger models are the answer. However, there are pitfalls: they require more resources, have a larger carbon footprint, and can sometimes be like using a sledgehammer to crack a nut. The success of the phi-1 model from "textbooks is all you need" serves as a testament to the prowess of smaller, well-tuned models.
I invite you to read the full paper if you want more granular details beyond the summary I shared here.
Crafting a Conscious AI Future
The rapid growth of AI brings forth ethical challenges, from accountability to potential biases. Imagine AI as a student. We wouldn't want this student to cram from every source blindly; rather, we'd prefer it to learn from the most refined, "textbook quality" materials. It's not just about getting smarter but about learning responsibly.
We're in an era where 'bigger is better' is often the mantra. But with the findings from the Microsoft Research team, there's a twist to the tale. Size isn't the only metric of success. Smaller models, like their newly introduced phi-1, can achieve remarkable feats without devouring our planet's precious resources. Especially as AI takes more roles in our daily lives we start depending on AI more and more.
By ensuring our AI gets its knowledge from the best sources, we're taking a step towards responsible, ethical, and, most importantly, beneficial AI for all. And if adopting smaller models that don't drain and require huge computation resources can get us as far then we should perhaps make "Smaller Smarter" our new mantra.



