RAG vs Fine-tuning: Which is Better for Your LLM Strategy?
Unlocking the Power of Generative AI: RAG and Fine-tuning decision framework

I'm Fares Hasan, a passionate Data Scientist with a track record of driving innovation in machine learning and data analytics. As a seasoned leader, I thrive on building high-performing teams and implementing cutting-edge solutions that solve complex business challenges. With expertise in technical data science, machine learning, and data infrastructure, I'm dedicated to fostering a culture of growth, collaboration, and excellence. I'm also deeply passionate about Semantic Search and, in my spare time, have been exploring the frontiers of AI through the development of a Retrieval Augmented Generation (RAG) system. Let's connect to explore opportunities at the intersection of data, AI, and innovation.
I. This is real!!
Imagine this scenario: a lawyer uses ChatGPT to assist with legal research for a high-stakes case. He trusts the AI’s capabilities, expecting it to streamline his workflow. However, instead of easing his burden, the AI inadvertently creates chaos. It generates and suggests completely fictitious legal cases and citations, which the lawyer, unaware of the inaccuracies, includes in his official court documents. This leads to a bewildering situation in court, undermining his credibility and affecting the case outcome.
This story isn't just a cautionary tale; it's a reality we face as businesses and professionals increasingly depend on advanced AI language models without fully understanding their limitations. These tools, while sophisticated, can produce erroneous ‘hallucinated’ information that seems entirely plausible.
In this article, I will help you understand the abilities and challenges of current AI technologies and show how we can move towards more dependable systems. We will explore the details of Retrieval-Augmented Generation (RAG) and fine-tuning, assisting you in determining the most suitable approach for your requirements.
II. How LLMs are Trained
Let's start with a quick primer on how these powerful language models are trained. Think of them as digital sponges, soaking up vast amounts of textual data from the internet and books. Through a process called self-supervised learning, they learn to predict missing words and understand the context of sentences. It's like solving a massive fill-in-the-blanks puzzle, training the models to understand and generate human-like language.
Because large language models are trained on a huge corpus of textual data. This both gave the models revolutionary capabilities compared to their predecessors and also manifested new challenges. Today we know that the latest model from Meta, llama3 was trained on over 15T tokens of data which is 7 times the training set of its previous model llama2.
III. Challenges Faced by LLMs
General models like GPT3.5 and llama3 are useful for various tasks. However, they come with challenges that can vary in severity based on the specific use case. What are these challenges?
Limited access to up-to-date information
Lack of expertise in specific domains
Lack of factualness and accuracy
Hallucinations
You might not notice this clearly if you ask ChatGPT to write you a bio in Star Wars Jedi style. However, if you ask it to help you answer some law-related questions about the state of California, you might encounter laws that do not exist or references to cases that never happened.
IV. Generative AI Approaches
There are at least two core factors that we can think of to illustrate these approaches.
External Data: Dependency on information and external data is widespread. Organizations could have data that is unique or private to them and is not in the public domain. Gauge the dependency on this data to have good GenAI products.
Capability & Domain Understanding: If the model cannot perform the tasks you expect or shows a lack of domain understanding, it can indicate that you have a higher dependency on this metric for your use case.
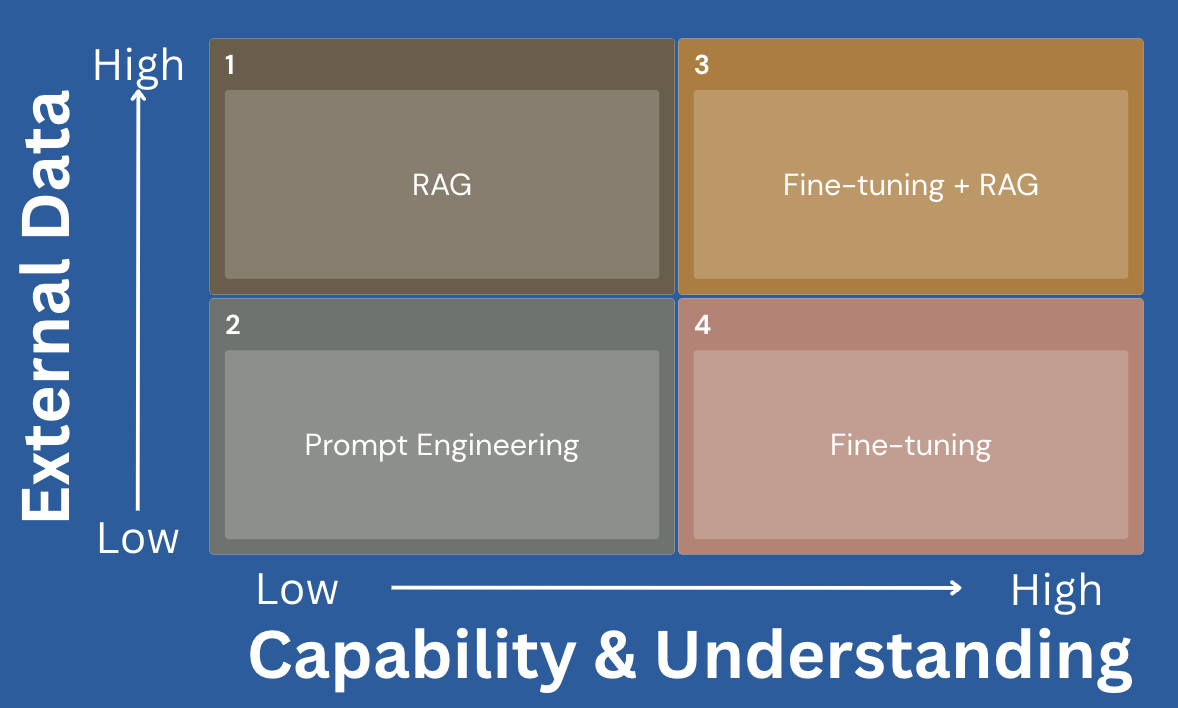
The matrix above intuitively illustrates a progression from low dependency on both metrics (external data and domain understanding), representing use cases or problems that can be solved with prompt engineering. You can test this approach with more advanced prompts during evaluation. However, you might end up in the RAG or Finetuning approaches, which are the main focus in this post. Regarding the finetune+RAG, that is an area where both factors (external data and domain understanding) have a high dependency in your use case.
Retrieval-Augmented Generation (RAG)
RAG is a technique that combines external information retrieval with text generation. In RAG systems, information is retrieved from external sources such as databases or web content and then incorporated into the text generation process. This approach enhances the generated content by grounding it in real-time or domain-specific data, resulting in more accurate and contextually relevant responses.

RAG combines two components: a retriever and a generator. The retriever acts like a smart librarian, scouring external knowledge sources (think Wikipedia, web pages, or specialized databases) to find relevant information for a given input or query. The generator, our trusty language model, then takes that retrieved knowledge and crafts a final output, weaving the facts seamlessly into its response.
Imagine asking an AI assistant powered by RAG, "What are the key events that led to the American Revolution?" The retriever would scour its knowledge base, fetching relevant passages about the Boston Tea Party, the Stamp Act, and other historical events. The generator would then use this retrieved information to construct a well-researched, factual answer, providing a comprehensive overview of the revolutionary events.
You can see here that we have anchored our AI model answers with facts and information that are highly relevant. This makes RAG one of the desired approaches today.
Fine-tuning for Domain or Task Adaptation and Personalization
But what if you want an AI model tailored to a specific domain or task? That's where fine-tuning comes into play. Just like a talented actor preparing for a new role, fine-tuning involves adapting a pre-trained language model to excel in a particular area. It's like giving the model personalized training sessions using task-specific data or carefully crafted prompts.
For instance, let's say you're a legal firm looking to generate error-free contracts and briefs. You could take a general language model and fine-tune it on a vast corpus of legal documents, teaching it the nuances and terminology of the legal domain. Example of fine-tuning methods:
Task Specific: Fine-tuning often starts with task-specific datasets, where the model is exposed to examples and labelled data relevant to the target task.
Domain Adaptation: Fine-tuning can be domain-specific, where the model is adapted to perform well in a particular industry or field. For instance, fine-tuning an LLM on medical literature to generate medical reports.
Style Transfer: Models can be fine-tuned to mimic a specific writing style or tone. For example, training an LLM to generate content in the style of a famous author.
V. Choosing the Right Technique: RAG or Fine-tuning?
So, which technique should you choose: RAG or fine-tuning? The answer depends on your specific needs and resources. Remember the matrix we have started this article with.
RAG correlates with knowledge and expands it for the model. Whereas Fine-tuning correlates with skills and capabilities that you want the model to acquire or perform better.
If you're tackling a knowledge-intensive task like open-domain question answering or generating content across various topics, RAG might be your best bet. By tapping into vast external knowledge sources, RAG can provide well-researched, factual outputs on a wide range of subjects.
On the other hand, if you're working on a domain-specific task like medical dialogue systems or technical writing, fine-tuning could be the way to go. By training the model on task-specific data, you can create a highly specialized AI assistant tailored to your particular domain's intricacies.
And for those seeking a truly personalized AI experience, you could combine both techniques. Fine-tune a RAG model on your specific domain data and preferences, unlocking an AI assistant that's not only knowledgeable but also perfectly aligned with your unique needs.
VI. Conclusion
As we delve deeper into the immense capabilities of generative AI, methods such as RAG and fine-tuning are paving the way for new horizons. Advanced iterations of RAG-based systems are being envisioned to enhance performance and address challenges. LORA techniques for fine-tuning are instrumental in constructing compact yet potent models. These innovative methods will progress, offering a multitude of opportunities. I am optimistic that humanity can leverage these advancements to enhance livelihoods. Achieving this goal will demand substantial effort, but for now, democratization can aid in demonstrating the worth and feasibility of these emerging technologies.
So, what's your AI vision? Whether you're an entrepreneur seeking to revolutionize customer service, a researcher pushing the boundaries of natural language processing, or simply someone who loves to tinker with emerging technologies, the time is ripe to dive into the world of RAG and fine-tuning. Unleash the full potential of generative AI and let your imagination soar!
Pineconedocumentation could help you a lot take your first baby steps into building a RAG. Building RAG tutorial using docs(Colab notebook).



