Beneath the hood: Fave Personalization

I'm Fares Hasan, a passionate Data Scientist with a track record of driving innovation in machine learning and data analytics. As a seasoned leader, I thrive on building high-performing teams and implementing cutting-edge solutions that solve complex business challenges. With expertise in technical data science, machine learning, and data infrastructure, I'm dedicated to fostering a culture of growth, collaboration, and excellence. I'm also deeply passionate about Semantic Search and, in my spare time, have been exploring the frontiers of AI through the development of a Retrieval Augmented Generation (RAG) system. Let's connect to explore opportunities at the intersection of data, AI, and innovation.
Photo by Stephen Leonardi on Unsplash
At Fave, we in the data science team actively research and innovate new ways to contribute to helping more SMEs become digital. The transformed data team went through a courageous process to expand its impact from business intelligence and reporting to building data products. Personalisation stands as one of the essential data products in Fave today, spreading its integration into our consumers, merchants and the Fave app. This motivated us to share how we built a robust recommendations engine in-house, given the unique characteristics of Fave’s offerings and products.
Fave’s most known products are FavePay, a mobile payment method designed to allow users to transact with offline merchants easily, and Fave Deals. The hyper-growth of Fave as a platform and the ubiquity of FavePay in Malaysia and Singapore today brings with it new challenges. In the early days, products (deals/discounts) were listed via hand-crafted localisation logic that brings the highest selling products to the top of the list for each user in a specific neighbourhood (around the user location). It worked but it couldn’t scale as Fave’s inventory covered more and more categories.
As we grew, we have observed a few shortcomings and opportunities:
- We have a long tail problem (a minority of items outperform the vast majority of items).
- New deals will get a slim opportunity to be seen by users compared to older top selling deals.
- We have so many offerings our users don’t know exist.
Long-tail

As the platform grew in its offerings, fewer and fewer people are able to know what they could find in our app. Users are fed with the highest selling items at the top of the list, so they become fixated on specific deals made visible to them and this feeds sales to that small subset of deals.
It's a real example of an iceberg where your customers can only see the tip of what is on offer. Even as we actively push other products via marketing channels, the iceberg body will still go unnoticed as the platform’s inventory grows.
Solution
In our analysis of the problem, we saw that our early logic was breeding into the problem by increasing the visibility of a small set of top selling products. The most optimal solution would be curating products based on something better than location and definitely not random. In the age of data science, that is what can be achieved by a recommendation engine. Personalisation could be one prescription to improve many aspects of our growth. Increasing the visibility of more deals will increase the potential of conversion while offering users a unique set of deals with the highest likelihood of being favoured by the user.
Challenges
Like most great ideas, there is always a but. Recommending Fave Deals, unlike Netflix’s movie recommendation or Amazon’s book recommendation, have some constraints that are relevant only to Fave.
At Fave, personalisation should adhere to the following constraints:
1- Live deals only; our deals are short-lived, and given the lifestyle pattern of Fave being an everyday app, we cannot afford recommending a product that is not live anymore.
2. Location proximity; as a lifestyle app, insights on user behaviour informs us how our users launch the app and transact. Users won’t travel too far out for a discount. We help users save by discovering deals that are around them.
3. Affordability; relevancy becomes pocket-size too. The price range of deals suggested to a user must not exceed what they can afford.
4. Diet restrictions; As much as possible, we optimise for dietary restrictions. For example, we won’t recommend meals that include pork or alcohol for Muslims.
There have been a few tools in the market that offers a recommendation engine as a service but the challenge is our use case and our circumstances might not necessarily be applicable by that service. In our scenario, there are limitations to using external services: those services probably cannot solve issues that arise in our specific context. For example, SurPRISE algorithms were handy to use but could not optimise for Fave’s constraints and therefore performed poorly in relevancy metrics.
We cannot simply pick a recommendation service or a model from a framework. Though that is easier to do, it is proven to score low in relevancy metrics.
Approach
Our solution was to implement a hybrid form of collaborative filtering (CF) recommendations. CF generates predictions about the users’ interests by looking at a collection of preference information from a group of users, hence collaboration. Bear in mind that these predictions (recommendations) are for a particular user, despite using information discovered from a group of users.
At the end of each day, the engine is fed with a set of data containing the following:
- Purchase date/time
- User behaviour in the app
- Clicked image
- Location
- Price range
- Merchant name
- Category of the item
- Demographics
- Device information
There are two types of data consumed by the model. These are explicit data which is simply transactional in nature: what deal has the user purchased in the past? and implicit data such as the items/images the user has clicked on. By combining explicit and implicit data types, we cover a wider spectrum of the user’s behaviour, tastes and preferences. There will always be a wealth of implicit data in every organisation as users will browse through several items and perhaps add a few to their wish lists before transacting. As a result the ratio of explicit to implicit is always 1:m. It is then strategically important to find ways to incorporate such implicit data into our systems and find ways to capitalise on it.
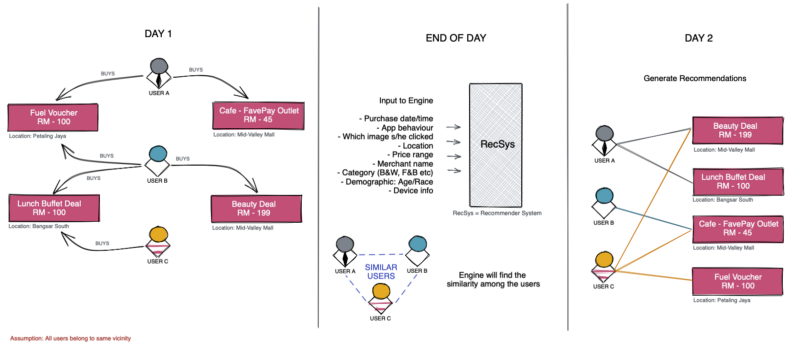
Fave recommendation engine concept
The model builds a user profile in a multi-dimensional space where a user is represented by a matrix of what they have purchased/shown interest in. Successfully applying machine learning depends on its data and the way data has been treated. “Applied machine learning’ is basically feature engineering” (Andrew Ng). So a user matrix can be only as good as the data we use to build it.
Semantic encoding
The features are what make machine learning algorithms work. Domain knowledge is the backbone of an effective features engineering process. Let’s take a simple example from our data, the category feature of each item is descriptive nominal data like the food category or the beauty category. We will use an encoding method to translate the nominal categorical values into numeric values in a typical machine learning problem. The one-hot-encoding method is one that is used for this purpose but it is limited in the depth of information it represents for our context.
Let’s think of a deal for a 2 person dinner in a Thai restaurant. It belongs to the food category. How would you compare this deal to another deal from the drinks category?

one-hot encoding problem
if Joe bought the 2 person Thai dinner ( food category) and Kamilla bought a deal for a 2 days staycation (travel category) and we have the signature drink deal to recommend. Which user is closer to the signature drink?
Looking at the image, you can see that the first two deals are similar but the similarity isn’t represented in the encoding. Both are food and beverages respectively and if we encode using the one-hot method, we will end up in a totally different conclusion mathematically. To understand this, you can calculate the euclidean distance between the food and drink (we calculate first 3 values for simplicity) — d=1.414214. If you tried the same calculator to compute the distance between food and travel, d is also 1.414214. By this calculation, you can see that one-hot encoding features adds a naive dimension without transcending any semantic information (human knowledge).
This problem can be easily solved by using some function to calculate semantic similarity in the two texts of category. In this context, imagine something like:
f(drink, food) = 0.79
Now the drink deal vector will look like this:
[0.79, 1, 0 ,0]
In our human knowledge, food and drink are similar, and using the one-hot encoding method alone will not give us such knowledge. The semantic similarity by mapping human sentence to a higher dimension space gives our basic encoding the details it needs to be meaningful.
What is the harm of using pure one-hot-encoding? Well, in an engine that doesn’t understand some aspects of the real world, we risk getting higher irrelevancy in our recommendations. If left with vague representations, the machine will fail to make sensible associations and will contradict our human world and that defies the purpose of building a recommendation engine: generating a relevant and interesting list of products for the user.
The machine if left with vague representations will fail to make sensible associations and will contradict our human world
Localisation of recommendations is another benefit gained by enhancing using location encoding. If we have 3 unique locations: Cyberjaya, Putrajaya, and Dengkil and our deal location is tagged as Dengkil, we will want to represent distances in our encoding and not arbitrary categorical values.
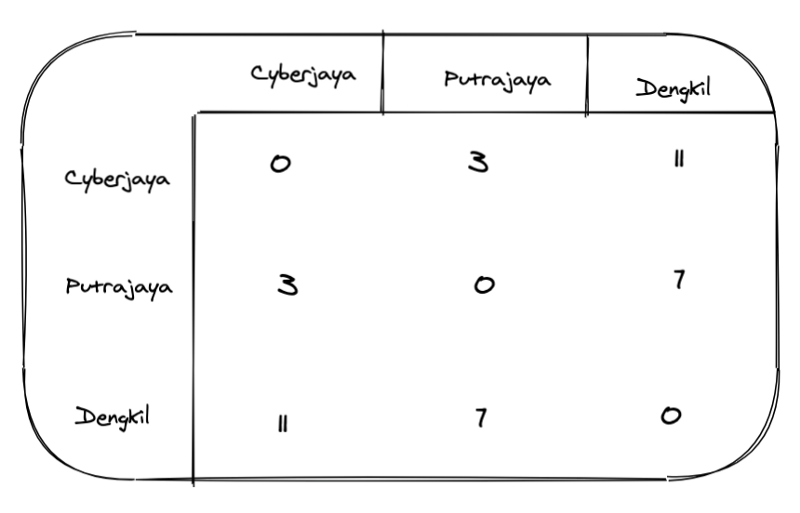
Distance matrix
If you have a deal tagged Cyberjaya you will have a vector [0, 3, 11] with such a distance-based encoding (you may even scale the values between 0–1). We allow for a more realistic representation of the real world by doing this.
You can see how Fave’s RecSys goes beyond and attributes its success to the amount of attention paid to the details and these details are best known by the team most familiar with the data. Our engine is localised and understands that you should get recommended something in Georgetown, Penang if you have been shopping around there and this is what brings our users back for more interesting deals.
Workflow
The whole workflow to get from data to recommendations is fully automated and we leverage Airflow as our workflow orchestration system. It takes 12 steps to reach the final recommendations that then can be consumed by the product. In Fave we are using multiple channels to deliver a personalised experience from direct marketing emails (EDMs), push notifications, through the home page of the Fave consumer app and across all possible channels.
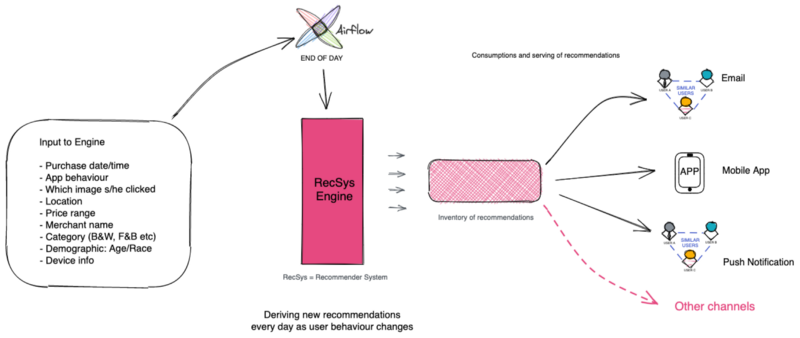
Fave RecSys workflow
In the early days of developing the engine we have tried generating recommendations on-the-fly whenever a user launches the app. The process was limiting in several ways like it worked only within the app and could not serve other channels. Changing our approach to pre-generating recommendations and storing them in an inventory for all users at least once a day brought several benefits. Another change we made was to utilise real-time data delivered by our on-the-fly transformations solution and that made it possible for tonight’s recommendations to train on this morning’s user-app interactions.

Personalisation across channels have increased our conversion by 7x
This inventory of recommendations made it possible to curate personalised content for EDMs and have time-optimised push notifications. For example, sending lunch deal recommendations via push notifications to users just before lunch time. In a way, integrating personalisation with marketing allowed the engine to be tweaked to focus on specific categories, specific price ranges or even specific type deals.
Summary
In our first beta test we couldn’t immediately recognise the difference brought by personalisation and we thought that we needed more time to monitor and validate the impact. For a data science project to come out of its POC phase and pass several experiments in production is a huge leap for us. In fact this is the first successfully productionised data project by our team and is Fave’s first ML model in the app. To get this far is not the rule but the exception, since most data science projects don’t go beyond the POC phase. The challenge isn’t just to do with the predictability of the model. There are also organisational and contextual factors that impact how likely a data science project will be productionised.
This project has matured over the course of several months and we are excited to democratise personalisation across Fave’s offerings. Today our users across 3 countries receive personalised EDMs and browse through a personalised home page. The future is personalised and so is your Fave experience.
Acknowledgement: the first ever attempt for recommendation in Fave was by Evonne and that paved the way for me to build upwards. Husein Zolkepli supported optimisations and scaling of the project. In Fave’s Data Science team, we are empowered to try new things and learn all the time and that is to the credit of Jatin Solanki. Over the course of this project there were countless others who influenced and supported this endeavour and I am grateful for every single one of you.




