Getting the Most Out of MLOps with ZenML: 1
MLOps is the practice of bringing together data science and engineering to operationalise machine learning.

I'm Fares Hasan, a passionate Data Scientist with a track record of driving innovation in machine learning and data analytics. As a seasoned leader, I thrive on building high-performing teams and implementing cutting-edge solutions that solve complex business challenges. With expertise in technical data science, machine learning, and data infrastructure, I'm dedicated to fostering a culture of growth, collaboration, and excellence. I'm also deeply passionate about Semantic Search and, in my spare time, have been exploring the frontiers of AI through the development of a Retrieval Augmented Generation (RAG) system. Let's connect to explore opportunities at the intersection of data, AI, and innovation.
TLDR
This series of articles focuses on getting the most out of MLOps using ZenML, an open-source framework that unifies the entire machine learning stack.
MLOps is critical to operationalizing and scaling ML models, leading to better decision-making and increased efficiency.
ZenML offers features like automated caching, data versioning, and metadata tracking that simplify the entire ML pipeline.
ZenML provides Continuous Training and Deployment (CT/CD) capabilities, a pipeline workflow architecture, and a ZenML stack that brings flexibility to handle pipelines.
By providing a unified and automated solution for ML workflows, ZenML empowers organizations to scale their ML models efficiently and effectively.
What's MLOps?
Databricks defines MLOps as a core function of Machine Learning engineering, focused on streamlining the process of taking machine learning models to production and then maintaining and monitoring them.
Why MLOps?
MLOps is important because it enables organizations to effectively operationalize and scale their machine learning models, leading to better decision-making, increased efficiency, and ultimately, greater business success.
Without MLOps, data scientists and engineers may struggle to deploy, monitor, and maintain models, leading to suboptimal performance, wasted resources, and an increased risk of errors.
For example, imagine a financial institution that wants to use machine learning to predict fraudulent transactions. If they don't have proper MLOps processes in place, they may struggle to deploy their model to production, monitor it for performance and accuracy, and update it as necessary. This could lead to missed fraud detection, false positives, and ultimately, financial losses.
On the other hand, with MLOps and a tool like ZenML, the financial institution can streamline the entire ML lifecycle, from data preparation to model training to deployment and beyond. They can easily monitor the performance of their model, detect and address drift, and continuously improve their predictions over time. This results in more accurate fraud detection, better decision-making, and ultimately, a stronger bottom line.
How does ZenML help with MLOps?
ZenML helps with MLOps by providing a comprehensive open-source framework that unifies the entire machine learning stack, making it easy to develop, train, and deploy models with a seamless transition from development to deployment.
With features such as local development with Python, automated caching, versioning of data, and automated metadata tracking, ZenML streamlines ML workflows and saves time and resources. Additionally, it allows for collaboration among teams and the ability to visualize ML workflows for improved design.
ZenML is more than just an MLOps framework - it's a holistic solution that seamlessly integrates the entire machine learning stack, empowering teams to develop, train, and deploy models with ease and efficiency. - ChadGPT
One of the key benefits of ZenML is its extensibility, as it can be tailored to meet specific needs and workflows. ZenML also provides a single place to link up and manage different MLOps tools, with support for popular infrastructure like Kubeflow, AWS Sagemaker, Azure ML, and Vertex AI GCP.
The new thing in town is called Continuous Training and Deployment (CT/CD) capabilities, allowing for end-to-end ML workflows that can deploy models in local or production-grade environments with integrations like MLFlow and Seldon Core. By providing a unified and automated solution for ML workflows, ZenML empowers organizations to scale their ML models efficiently and effectively.
A brief overview of the ZenML workflow
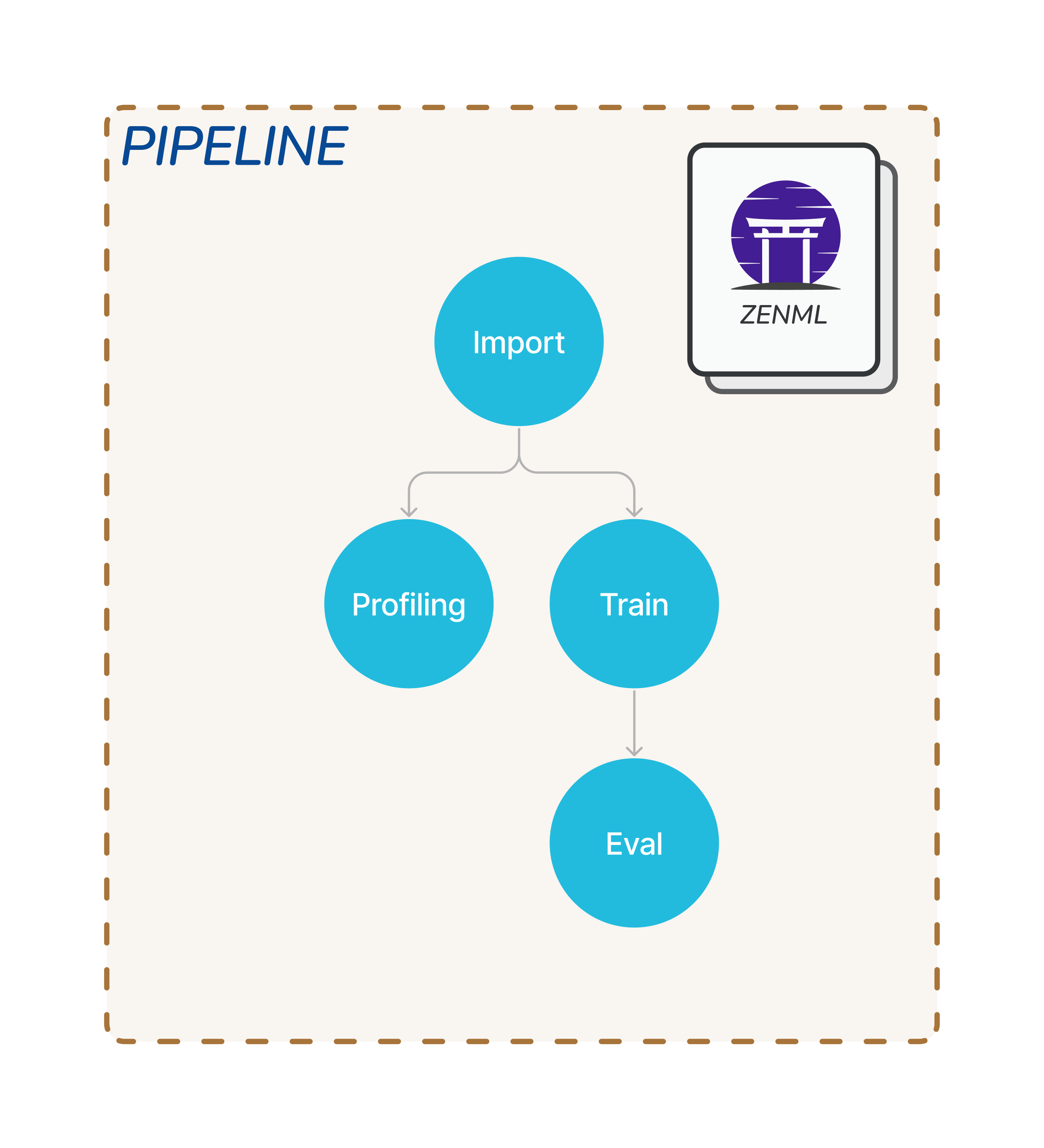
Steps & Pipelines
ZenML is built around the pipeline workflow architecture. The simplest unit of the workflow is a step which you can look at as a single process or Python function. You can create your steps in any way that aligns with your use case, for example, you may have an importer step. The importer step imports data, and then preprocessing steps which will apply to preprocess your data and so on. These steps can have dependencies among your steps where some steps will depend on the output of another step. The collection of a few steps can form a pipeline.
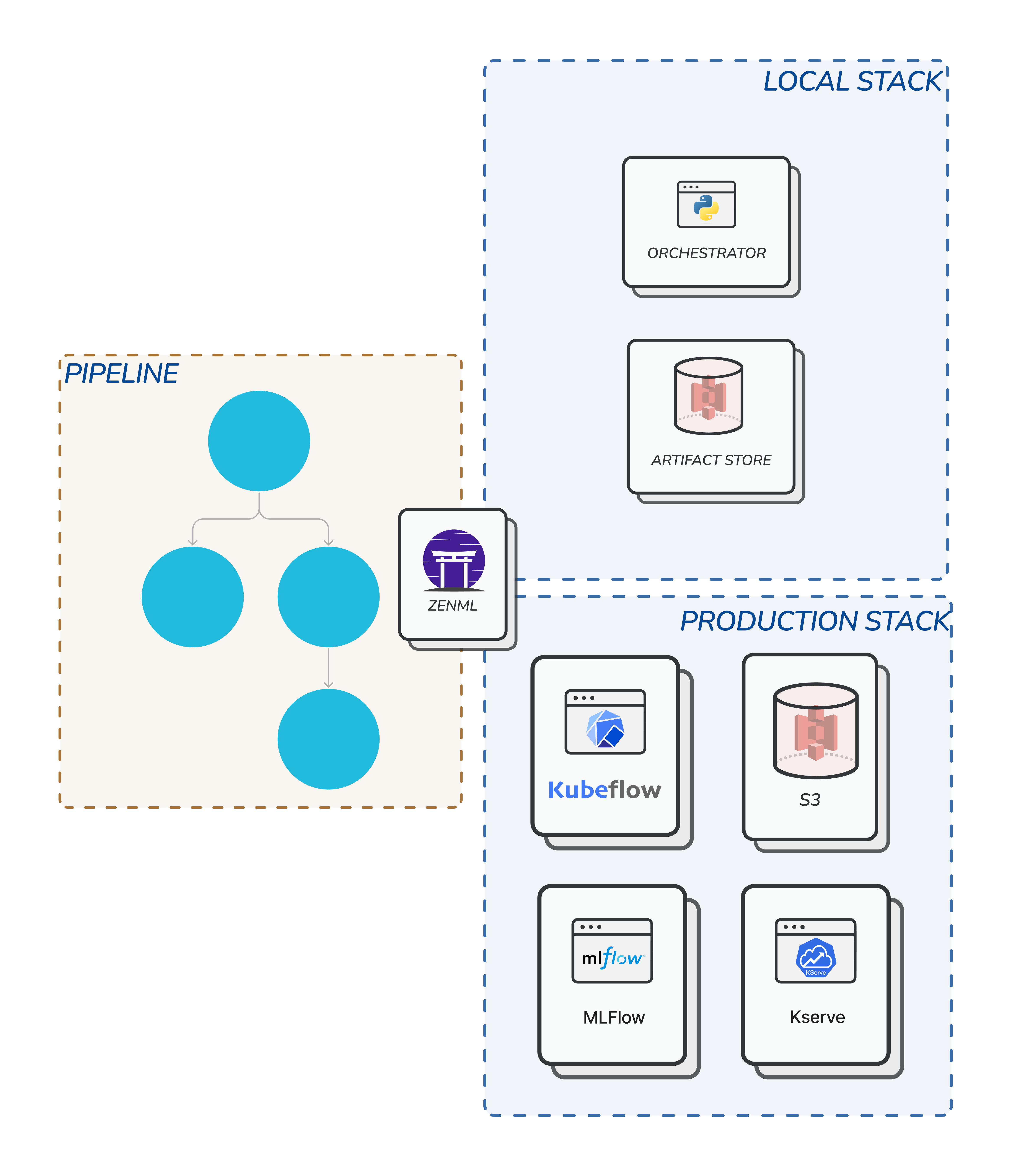
Stacks
So to handle your pipeline you can use ZenML stack which is an abstract layer built for this purpose. For example, you may have a stack with components to handle artefact storage, orchestrator and experiment tracker. Upon running the pipeline this stack will handle the process. This brings flexibility in the sense that you may have a local stack for pipeline or a project for testing, and there is a remote stack which is for production.
Summary
MLOps is an essential part of Machine Learning engineering that involves streamlining the process of taking ML models to production and maintaining and monitoring them. Without MLOps, organizations risk suboptimal performance, wasted resources, and increased error risks. ZenML provides an open-source solution that simplifies the entire ML pipeline and provides features like automated caching, data versioning, and automated metadata tracking. It seamlessly integrates the entire machine learning stack and supports popular infrastructure like Kubeflow, AWS Sagemaker, Azure ML, and Vertex AI GCP. ZenML also offers Continuous Training and Deployment (CT/CD) capabilities for end-to-end ML workflows that deploy models in local or production-grade environments. The ZenML workflow is built around pipeline architecture with a collection of steps that form a pipeline. ZenML stack is an abstract layer built to handle these pipelines, bringing flexibility in the sense of having a local stack for a pipeline, a project for testing, and a remote stack for production.




